golang经典知识问题
https://www.iamshuaidi.com/8912.html
1.与其他语言相比,使用 Go 有什么好处?
1.方便快捷的交叉编译能力,可二进制快速部署;
2.强大的并发机制GPM
3.对网络编程及其友好;
4.适合基础设施开发
5.语法简单
Golang的问题:
1.CGO不够完美,导致GO不能很好利用现有的C/C++资源,例如性能和交叉编译;
2.对错误的处理机制繁琐;
3.语言的表达能力不如其他语言便捷;
2.Golang 使用什么数据类型?
go有基础类型,指针类型,引用类型本质还是指针
x := complex(1, 2) // 1+2i ,默认128位
var y complex64 = complex(1, 2) // 1+2i
fmt.Println(x)
fmt.Println(y)3.Go 程序中的包是什么?
在GO语言中,类似于有一个命名空间的概念,用于将一堆相关的数据结构方法等放到一块.
4.Go 支持什么形式的类型转换?将整型转换字符串
go强调同类型才能转换,包括断言和数据(目标类型)的方式
var a int = 3
var str string = strconv.Itoa(a)
fmt.Println(str)
_ = fmt.Sprintf("%d", a) //性能低
5.断言的方式
从interface转换为具体类型,反过来是不行的.
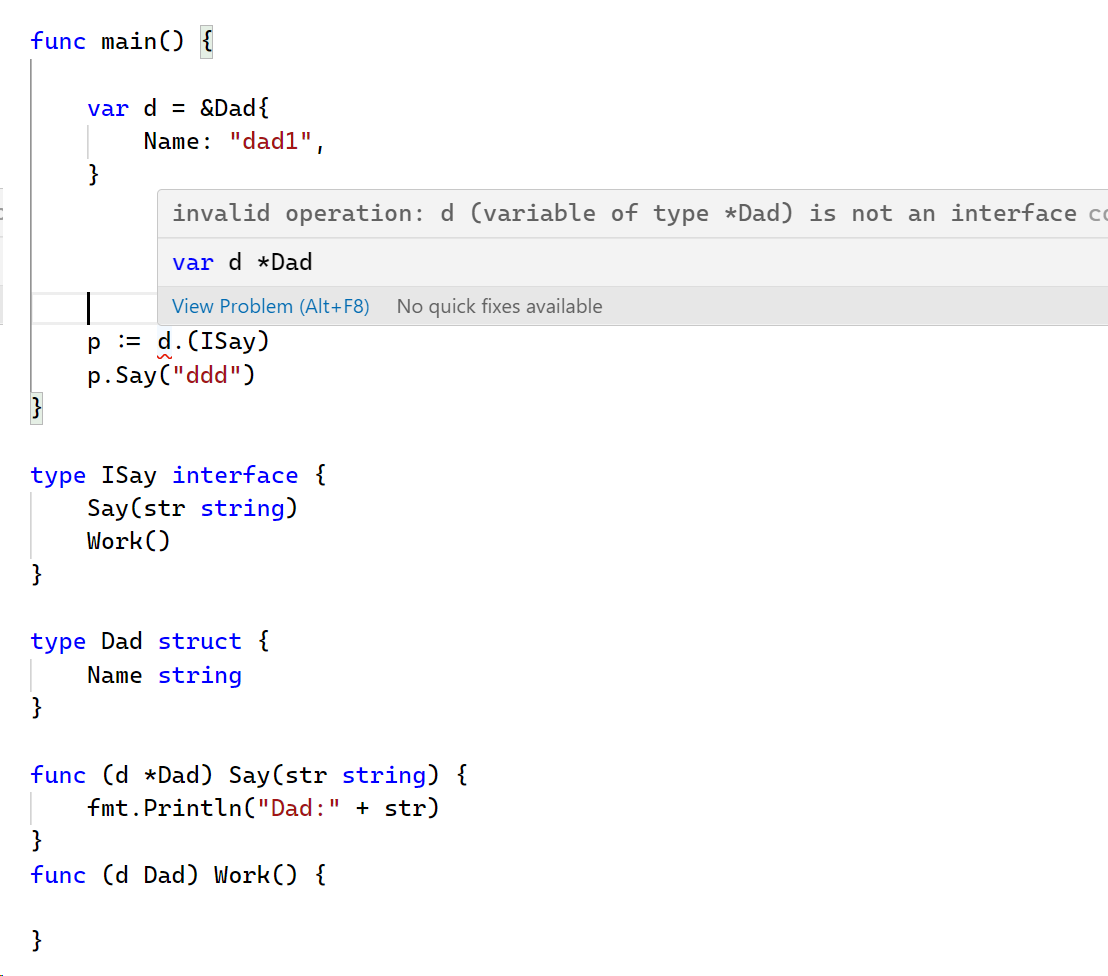
变量b :=变量a.(类型) //断言失败会panic
变量b, ok = 变量a.(类型) //可以通过ok判断
switch variable := variable.(type){
default:
fmt.Printf("unexpected type %T", variable)
case string:
fmt.Printf("type is %T, variable = %v", variable, variable)
}
5.指针类型拥有值类型的接收器方法,不是反过来.
6.Go 两个接口之间可以存在什么关系
如果两个接口有相同的方法列表,那么他们就是等价的,可以相互赋值。
如果接口 A 的方法列表是接口 B 的方法列表的子集,那么接口 B 可以赋值给接口A。
接口查询是否成功,要在运行期才能够确定。
7.Go 语言当中 Channel(通道)有什么特点,需要注意什么?
使用简单的 make 调用创建的通道叫做无缓冲通道,但 make 还可以接受第二个可选参数,一个表示通道容量的整数。如果容量是 0,make 创建一个无缓冲通道。
ch = make(chan int) // 无缓冲通道
ch = make(chan int, 0) // 无缓冲通道
ch = make(chan int, 3) // 容量为 3 的缓冲通道1.无缓冲通道上的发送操作将被阻塞,直到另一个 goroutine 在对应的通道上执行接受操作,这时值传送完成,两个 goroutine 都可以继续执行。
2.相反,如果接受操作先执行,接收方 goroutine 将阻塞,直到另一个 goroutine 在同一个通道上发送一个值。
3.使用无缓冲通道进行的通信导致发送和接受操作, goroutine 同步化。因此,无缓冲通道也称为同步通道。当一个值在无缓冲通道上传递时,接受值后发送方 goroutine 才能被唤醒。
缓冲通道上的发送操作在队列的尾部插入一个元素,接收操作从队列的头部移除一个元素。如果通道满了,发送操作会阻塞所在的 goroutine 直到另一个 goroutine 对它进行接收操作来留出可用的空间。反过来,如果通道是空的,执行接收操作的 goroutine 阻塞,直到另一个 goroutine 在通道上发送数据。
a.如果给一个 nil 的 channel 发送数据,会造成永远阻塞。
b.如果从一个 nil 的 channel 中接收数据,也会造成永久阻塞。 给一个已经关闭的 channel 发送数据, 会引起 panic。
c.从一个已经关闭的 channel 接收数据, 如果缓冲区中为空,则返回一个 零 值。
8.Go 语言中 cap 函数可以作用于那些内容
-
array(数组)
-
slice(切片)
-
channel(通道)
注意切不可用于map,因为map的容量动态调整.
9.go convey 是什么?一般用来做什么
-
go convey 是一个支持 golang 的单元测试框架
-
go convey 能够自动监控文件修改并启动测试,并可以将测试结果实时输出 到 Web 界面
-
go convey 提供了丰富的断言简化测试用例的编写
10.Go 语言当中 new 和 make 有什么区别吗
new 的作用是初始化一个纸箱类型的指针 new 函数是内建函数,函数定义:
func new(Type) *Type
使用 new 函数来分配空间
传递给 new 函数的是一个类型,而不是一个值
返回值是指向这个新非配的地址的指针
make 的作用是为 slice, map or chan 的初始化,
func make(Type, size IntegerType) Type make(T, args)函数的目的和 new(T)不同 仅仅用于创建 slice, map, channel 而且返回对应的实例
11.Printf(),Sprintf(),FprintF() 都是格式化输出,有什么不同
| a | 作用 |
|---|---|
| Printf | fmt.Printf(format string, a ...any) |
| Sprintf | str = fmt.Sprintf("%d", num1) |
| Fprintf | fmt.Fprintf(w io.Writer, format string, a ...any) |
Fprintf通常用于输出设备,在go里面实现了Writer接口即可.
type Writer interface {
Write(p []byte) (n int, err error)
}12.Go 语言当中数组和切片的区别是什么
简单而言,切片是对数组操作的封装,加上扩容机制.
13.Go 语言当中值传递和地址传递(引用传递)如何运用 有什么区别 举例说明
严格的GO中只有值传递,所谓的引用传递只是因为指针的缘故.
14.Go 语言当中数组和切片在传递的时候的区别是什么
切片的数据结构:Data数组指针,Len数据可达到的长度,Cap底层容量,
在GO里只有值传递,因为切片的数据成员是指针,所以不会存在拷贝数组的情况.
type SliceHeader struct {
Data uintptr //引用数组指针地址
Len int // 切片的目前使用长度
Cap int // 切片的容量
}15.Go 语言是如何实现切片扩容的
https://www.bmabk.com/index.php/post/167823.html
func main() {
arr := make([]int, 0)
for i := 0; i < 2000; i++ {
fmt.Println("len 为", len(arr), "cap 为", cap(arr))
arr = append(arr, i)
}
}
// oldPtr = pointer to the slice's backing array
// newLen = new length (= oldLen + num)
// oldCap = original slice's capacity.
// num = number of elements being added
// et = element type
func growslice(oldPtr unsafe.Pointer, newLen, oldCap, num int, et *_type) slice {
}
newcap := oldCap
doublecap := newcap + newcap
if newLen > doublecap {
newcap = newLen
} else {
const threshold = 256
if oldCap < threshold {
newcap = doublecap
} else {
// Check 0 < newcap to detect overflow
// and prevent an infinite loop.
for 0 < newcap && newcap < newLen {
// Transition from growing 2x for small slices
// to growing 1.25x for large slices. This formula
// gives a smooth-ish transition between the two.
newcap += (newcap + 3*threshold) / 4
}
// Set newcap to the requested cap when
// the newcap calculation overflowed.
if newcap <= 0 {
newcap = newLen
}
}
}
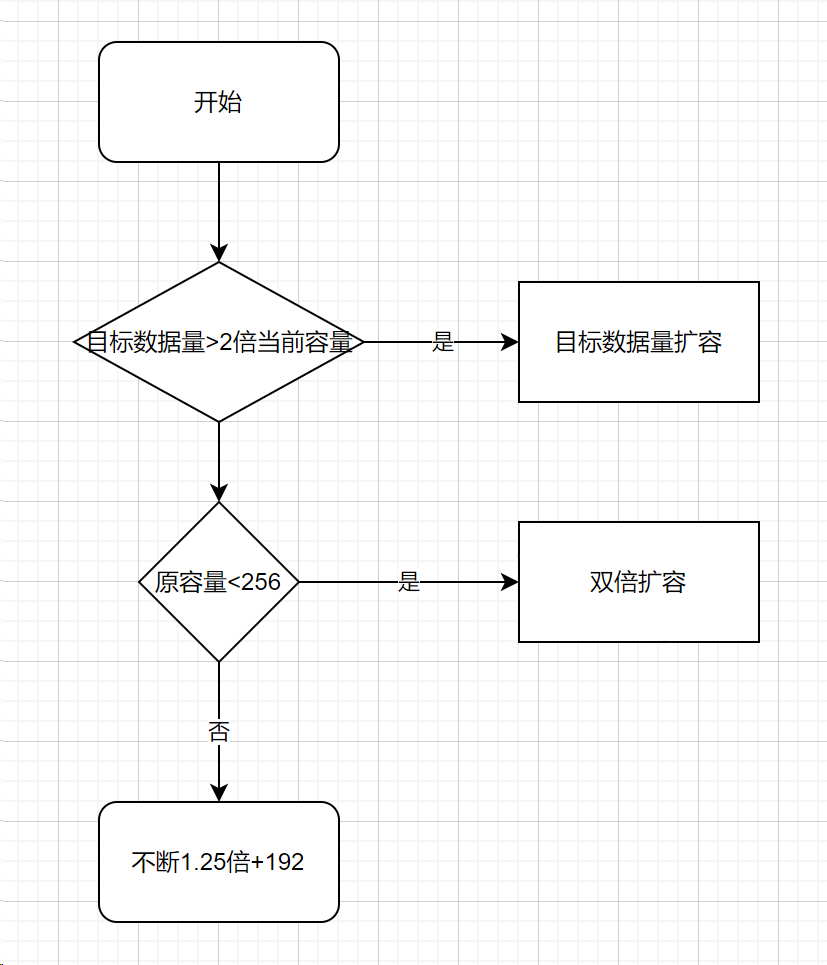
如果最终容量计算值溢出,则最终容量就是新申请容量
16.defer的知识点
1.多defer的执行本质就是一个栈,后进先出
2.正常情况下,return之后才会执行defer
3.函数有返回值变量名,这首先这个变量初始化为零值,当这个变量的生命周期会在defer执行完后
4.函数里面的defer不是总会执行的,panic后面的defer是无法执行到的.(无论外面有没有捕捉)
5.如果捕捉,那么调用这个函数的外层函数就能正常执行
func main() {
defer_call()
fmt.Println("main 正常结束")
}
func defer_call() {
defer func() { fmt.Println("defer: panic 之前1") }()
defer func() { fmt.Println("defer: panic 之前2") }()
panic("异常内容") //触发defer出栈
defer func() { fmt.Println("defer: panic 之后,永远执行不到") }()
}
结果
defer: panic 之前2
defer: panic 之前1
panic: 异常内容
//... 异常堆栈信息
func main() {
defer_call()
fmt.Println("main 正常结束")
}
func defer_call() {
defer func() {
fmt.Println("defer: panic 之前1, 捕获异常")
if err := recover(); err != nil {
fmt.Println(err)
}
}()
defer func() { fmt.Println("defer: panic 之前2, 不捕获") }()
panic("异常内容") //触发defer出栈
defer func() { fmt.Println("defer: panic 之后, 永远执行不到") }()
}
结果
defer: panic 之前2, 不捕获
defer: panic 之前1, 捕获异常
异常内容
main 正常结束
**defer里面再次出现panic,就会屏蔽了外面的panic**
func main() {
defer func() {
if err := recover(); err != nil {
fmt.Println(err)
} else {
fmt.Println("fatal")
}
}()
defer func() {
panic("defer panic")
}()
panic("panic")
}
结果 defer panic
7.defer后面的函数里面参数是子函数,那么子函数会先执行
func function(index int, value int) int {
fmt.Println(index)
return index
}
func main() {
defer function(1, function(3, 0))
defer function(2, function(4, 0))
}
3
4
2
1
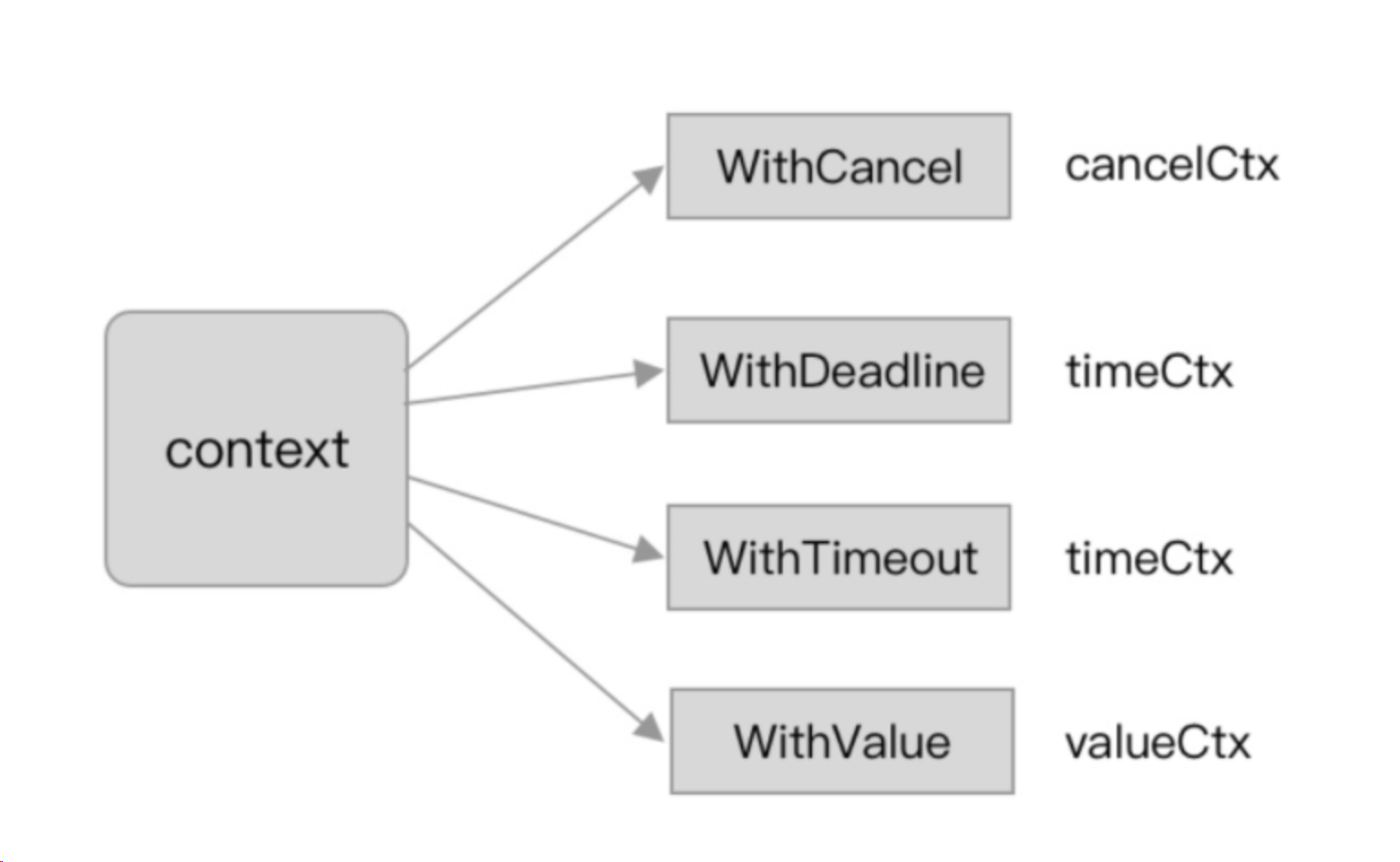
16.Context的知识点
用于在协程之间传递数据消息.而形成的一个解决方案.前面三种类型通过close chan的方式传递消息,value类型通过key value传递数据.
https://cloud.tencent.com/developer/article/1996581
func testValueCtx() {
type contextKey string
f := func(ctx context.Context, k contextKey) {
if v := ctx.Value(k); v != nil {
fmt.Println("found value:", v)
return
}
fmt.Println("key not found:", k)
}
k := contextKey("小米")
ctx := context.WithValue(context.Background(), k, "小米value")
f(ctx, k)
f(ctx, contextKey("小红"))
}
func testCancelCtx() {
ctx, cancelFn := context.WithCancel(context.Background())
go func(ctx context.Context) {
fmt.Println("go func in")
for {
select {
case <-ctx.Done():
{
fmt.Println(time.Now())
fmt.Println("go func get cancel")
goto end
}
}
}
end:
}(ctx)
fmt.Println(time.Now())
time.Sleep(3 * time.Second)
fmt.Println(time.Now())
cancelFn()
time.Sleep(300 * time.Second)
}17.map的原理
https://blog.m.fastnat.top?p=522
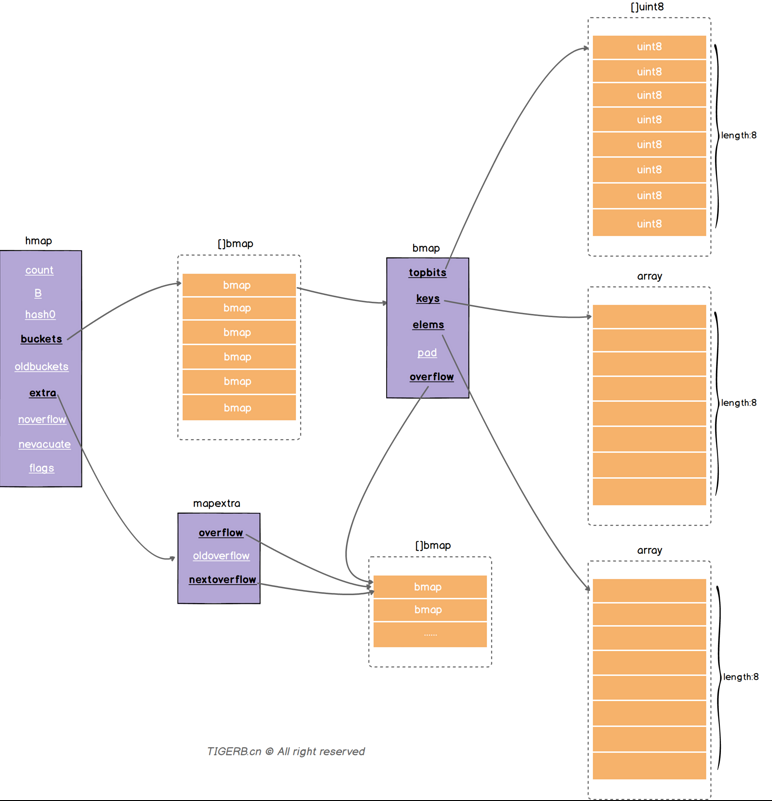
map本质是一个hmap的指针类型的语法糖
hmap里面还有表示当前map的整体情况的字段:
- count,元素个数
- B,2^B=brukets的长度, 桶的个数因子
- hash0因子
- bruckets: 桶的数组指针,
- extra:溢出桶的数组指针
一个桶就是一个bmap,一个bmap里面有两个8个长度的数组,分别装key,和value,
(桶装水,从低到高)
一个Key会根据hash(key)低B位确定使用哪一个桶,
在命中哪个桶之后,又会根据 hash 值的高 8 位来决定是 8 个 key 里的哪个位置。
如果hash 冲突,即该位置上已经有其他 key 存在了,则会去其他空位置。如果8个全都满了,
则使用bmap上的 overflow 指针指向一个新的桶,重复刚刚的寻找步骤。
Golang 选择哈希算法时,根据 CPU 是否支持 AES 指令集进行判断 ,如果 CPU 支持 AES 指令集,则使用 Aes Hash,否则使用 memhash。
扩容机制(装满因子):元数个数/桶的个数
https://jishuin.proginn.com/p/763bfbd5da65
装满因子 loadFactor := count / (2^B) //count表示map的元素个数,2^B表示桶的个数
map的扩容有2种机制
1、loadFactor > 6.5,触发double扩容,迫使元素顺序变化,所以为啥map要乱序
2、否则看溢出桶的情况:
桶的个数<2^15时,只要溢出桶比桶多,那么等量扩容
桶的个数>2^15,只要溢出桶的个数也超过这个数就会等量扩容.
如果桶达到这个基准,溢出桶比2^15多,也会等量扩容.
当 B 小于 15,,如果溢出桶的数量> 2^B;
当 B >= 15,如果溢出桶的数量 >2^15,触发等量扩容
一个Key会根据hash(key)低位确定使用哪一个桶,然后根据低N位hash确定对应的数据存放桶的位置,
https://studygolang.com/articles/32943
N=2^b
map 的 key、value 是存在 buckets 数组里的,每个 bucket 又可以容纳 8 个 key 和 8 个 value。当要插入一个新的 key - value 时,会对 key 进行 hash 运算得到一个 hash 值,然后根据 hash 值 的低几位(取几位取决于桶的数量,比如一开始桶的数量是 5,则取低 5 位)来决定命中哪个 bucket。
在命中某个 bucket 后,又会根据 hash 值的高 8 位来决定是 8 个 key 里的哪个位置。如果不巧,发生了 hash 冲突,即该位置上已经有其他 key 存在了,则会去其他空位置寻找插入。如果全都满了,则使用 overflow 指针指向一个新的 bucket,重复刚刚的寻找步骤。
从上面的流程可以看出,在判断 hash 冲突,即该位置是否已有其他 key 时,肯定是要进行比较的,所以 key 必须得是可比较类型的。像 slice、map、function 就不能作为 key。
- Go的Map遍历结果“无序”
-- 遍历Map的索引的起点是随机的 - Go的Map本质上是“无序的”
无序写入
正常写入(非哈希冲突写入)
哈希冲突写入
扩容
成倍扩容迫使元素顺序变化
等量扩容
18. Go 1.21 新增 runtime.Pinner
为了解决和C交互时,传给C的数据被GC盯上,以及内存地址发生变化,
runtime.KeepAlive() 保证不会被垃圾回收,但是对象的地址可能会有变化,从一个位置移动到了另外一个位置.
Pin保证的是对象不会被运行时移动,这样对象的地址就会保持不变,可以为cgo, unsafe安全的处理
19.chan总结
ch3 := make(chan<- int, 10) // 初始化一个只写的channel
ch4 := make(<-chan int, 10) // 初始化一个只读的chaannel- 排除缓冲区的情况,chan的读写都会将当前操作的goroutine加入等待读/写 队列中
- 为什么go 不提供channel的 isclosed方法,
因为当你获取到是当前这一时刻的状态,你再用的时候就可能变了,严重的安全隐患.func IsClosed[T any](ch <-chan T) (bool, T) { select { case v, ok := <-ch: return !ok, v default: { var value T return false, value } } }chan close 原则
- 永远不要尝试在读取端关闭 channel ,写入端无法知道 channel 是否已经关闭,往已关闭的 channel 写数据会 panic ;
- 一个写入端,在这个写入端可以放心关闭 channel;
- 多个写入端时,不要在写入端关闭 channel ,其他写入端无法知道 channel 是否已经关闭,关闭已经关闭的 channel 会发生 panic (你要想个办法保证只有一个人调用 close);
- channel 作为函数参数的时候,最好带方向;
其实这些原则只有一点:一定要是安全的时候才能去 close channel 。
chan里面的结构
一个环形队列,
一个发送等待g队列,
一个接收等待g队列,
以及描述chan情况的字段,
它最终还是靠着mutex实现同步的
type hchan struct {
qcount uint // 循环队列中数据个数
dataqsiz uint // 循环队列的总大小
buf unsafe.Pointer // 指向大小为dataqsize的包含数据元素的数组指针,即环形队列的指针
elemsize uint16 // 数据元素的大小
closed uint32 // 代表channel是否关闭
elemtype *_type // _type代表Go的类型系统,elemtype代表channel中的元素类型
sendx uint // 发送索引号,初始值为0
recvx uint // 接收索引号,初始值为0
recvq waitq // 接收等待G队列,存储试图从channel接收数据(<-ch)的阻塞goroutines
sendq waitq // 发送等待G队列,存储试图发送数据(ch<-)到channel的阻塞goroutines
lock mutex // 加锁能保护hchan的所有字段,包括waitq中sudoq对象
}
panic出现的常⻅场景还有:
- 关闭值为nil的channel
- 关闭已经被关闭的channel
- 向已经关闭的channel写数据
读写nil类型的chan会导致永久阻塞
20.高效求算文件夹大小
func main() {
var sum int64 = 0
//并发数 concurrency
var concurrency = runtime.NumCPU() * 100
var concurrencyChan = make(chan int, concurrency)
var wg sync.WaitGroup // 创建一个等待组,用于等待所有的goroutine结束
concurrencyChan <- 1
wg.Add(1) // 增加等待组的计数
scanDir("D:\\download", &sum, &wg, concurrencyChan)
wg.Wait() // 等待所有的goroutine结束
fmt.Println(sum) //
}
func scanDir(dir string, sumSize *int64, wg *sync.WaitGroup, concurrencyChan chan int) {
defer func() {
wg.Done()
<-concurrencyChan
}()
files, err := os.ReadDir(dir)
if err != nil {
fmt.Println(err)
return
}
for _, file := range files {
if file.IsDir() {
fileFullName := path.Join(dir, file.Name())
concurrencyChan <- 1
wg.Add(1)
go scanDir(fileFullName, sumSize, wg, concurrencyChan)
} else {
v, err := file.Info()
if err == nil {
atomic.AddInt64(sumSize, v.Size())
}
}
}
}
redis mysql
https://www.bmabk.com/index.php/post/60746.html