再论GO语言中的内存对齐
1.为什么需要内存对齐
1.1 提升CPU访问内存的效率
CPU访问内存通常是按照机器固定长度进行读取,如4字节,8字节,如果不按照固定长度读取到寄存器,那么就存在各种不必要的规则进行取舍和更多内存访问次数
1.2 增加程序的可移植性
不同的硬件平台,对于内存数据地址的读取,存在不一样的规则限制:有的可以任意访问任意地址的数据,有的只能在特定地址上存取特定类型数据,硬件平台的不一样.所以在编译器阶段解决这个问题就显得更加重要.
2.内存对齐规则
2.1 对齐系数和有效对齐值
对齐系数:在不同平台上,不同编译器拥有默认的对齐系数,例如32位系统,gcc中默认#pragma pack(4),也可以通过预编译命令#pragma pack(n),n = 1,2,4,8,16来改变这一系数。
有效对齐值:是给定值#pragma pack(n)和结构体中最长数据类型长度中较小的那个。有效对齐值也叫对齐单位。
2.2 内存对齐的规则
规则1:结构体第一个成员的偏移量为0,以后每个成员的偏移量offset=min(成员大小,有效对齐值)*N
规则2:最终的结构体所占内存=有效对齐值*N (N为整数)
3.演示代码和成员位置
3.1 GO中两个辅助我们了解内存布局的函数
unsafe.Alignof 返回对应类型所需要的 有效对齐值
unsafe.Offsetof 函数的参数必须是一个字段 x.f,然后返回 f 字段相对于 x 起始地址的偏移量,包括可能的空洞。
package main
import (
"fmt"
"unsafe"
)
type A struct {
a int8
b int16
c int8
}
type B struct {
a int8
b int8
c int16
}
type C struct {
a int8
b int16
c struct{}
}
func main() {
a := A{1, 2, 3}
b := B{1, 2, 3}
c := C{}
fmt.Println(unsafe.Sizeof(a), unsafe.Alignof(a), unsafe.Offsetof(a.b)) // 6 2 2
fmt.Println(unsafe.Sizeof(b), unsafe.Alignof(b), unsafe.Offsetof(b.b)) // 4 2 1
fmt.Println(unsafe.Sizeof(c), unsafe.Alignof(c), unsafe.Offsetof(c.a), unsafe.Offsetof(c.b), unsafe.Offsetof(c.c)) // 6 2 0 2 4
fmt.Println(unsafe.Sizeof(c.c)) //0
}
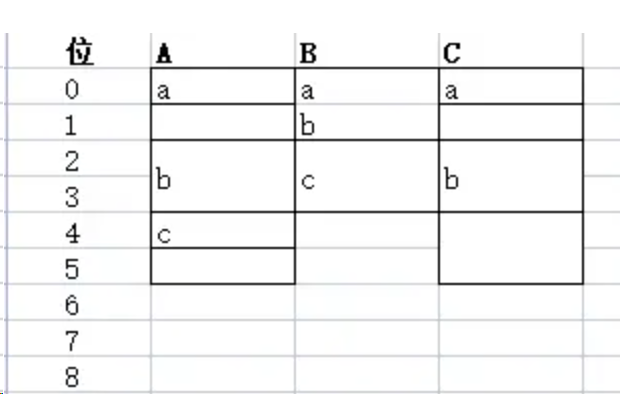
空结构体作为结构体的内置字段:当变量位于结构体的前面和中间时,不占用内存;当该变量位于结构体的末尾位置时,需要进行内存对齐,内存占用大小和前一个变量的大小保持一致。偏移地址有点怪异,此处不解.......
4.场景利用
节约内存应用
和C/C++在cgo配合使用时,需要留意.
参考内容:
unsafe.Sizeof, Alignof 和 Offsetof · Go语言圣经 (studygolang.com)
type A struct {
a int8
b int64
c int8
}
a := A{1, 2, 3}
set GOARCH=386
fmt.Println(unsafe.Sizeof(a))//16谁给解释下