还是把map给聊明白了吧
map概述
map作为go中最复杂的数据结构之一,有必要弄清楚,毕竟可以用来装逼.虽然map的内存泄露隐患问题至今没有解决,我们还需要容忍容忍.大爷的:谷歌都没有办法了吗?
Go中的map是一个指针,占用8个字节,指向hmap结构体; 源码src/runtime/map.go中可以看到map的底层结构.
hmap包含若干个结构为bmap的bucket数组。每个bucket底层又都采用链表串起来。接下来,我们来详细看下map的结构
// A header for a Go map.
type hmap struct {
// 代表哈希表中的元素个数,调用len(map)时,返回的就是该字段值。
count int
// 状态标志,下文常量中会解释四种状态位含义。
flags uint8
// buckets(桶)的对数log_2
// 如果B=5,则buckets数组的长度 = 2^5=32,意味着有32个桶
B uint8
// 溢出桶的大概数量
noverflow uint16
// 哈希种子
hash0 uint32
// 指向buckets数组的指针,数组大小为2^B,如果元素个数为0,它为nil。
buckets unsafe.Pointer
// 如果发生扩容,oldbuckets是指向老的buckets数组的指针,老的buckets数组大小是新的buckets的1/2;非扩容状态下,它为nil。
oldbuckets unsafe.Pointer
// 表示扩容进度,小于此地址的buckets代表已搬迁完成。
nevacuate uintptr
// 这个字段是为了优化GC扫描而设计的。当key和value均不包含指针,并且都可以inline时使用。extra是指向mapextra类型的指针。
extra *mapextra
}
```


``` go
----+-----------------+-. bmp
^ | bucket0 | |------> +------------+
| +-----------------+-' | tophash0-7 |
2^h.B | ....... | +------------+
| +-----------------+ | key0-7 |
v | bucket2^h.B - 1 | +------------+
----+-----------------+ | value0-7 |
+------------+ -.
|overflow_ptr| |-----> new bucket address
// A bucket for a Go map.
type bmap struct {
tophash [bucketCnt]uint8
// len为8的数组
// 用来快速定位key是否在这个bmap中
// 桶的槽位数组,一个桶最多8个槽位,如果key所在的槽位在tophash中,则代表该key在这个桶中
}
//底层定义的常量
const (
bucketCntBits = 3
bucketCnt = 1 << bucketCntBits
// 一个桶最多8个位置
)
但这只是表面(src/runtime/hashmap.go)的结构,编译期间会给它加料,动态地创建一个新的结构:
type bmap struct {
topbits [8]uint8
keys [8]keytype
values [8]valuetype
pad uintptr
overflow uintptr
// 溢出桶
}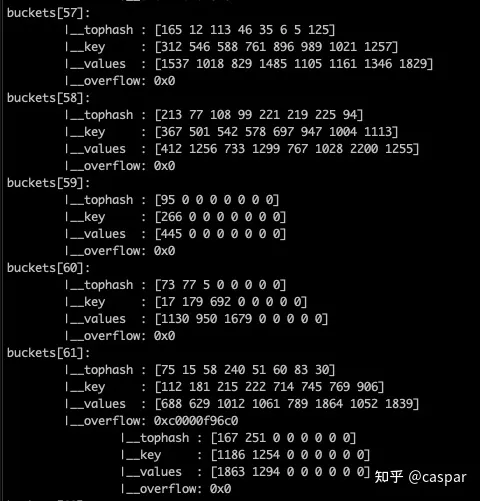
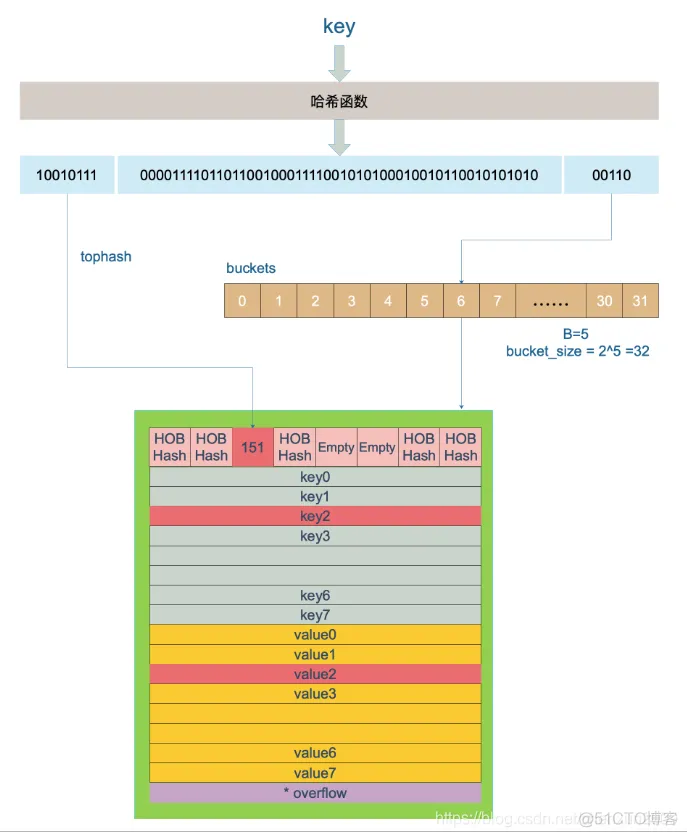
存取数据的逻辑
一个桶就是一个bmap,一个bmap里面有两个8个长度的数组,分别装key,和value,
(桶装水,从低到高)
一个Key会根据hash(key)的二进制,低B位确定使用哪一个桶,
在命中哪个桶之后,又会根据 hash 值的高8 位来决定是 8 个 key 里的哪个位置。
如果hash 冲突,即该位置上已经有其他 key 存在了,则会去其他空位置。如果8个全都满了,
则使用bmap上的 overflow 指针指向一个新的桶,重复刚刚的寻找步骤。
Golang 选择哈希算法时,根据 CPU 是否支持 AES 指令集进行判断 ,如果 CPU 支持 AES 指令集,则使用 Aes Hash,否则使用 memhash。
扩容机制
https://blog.51cto.com/u_15133569/5669069
1.为什么要库容->go里面的map需要采用扩容来满足查询性能
使用哈希表的目的就是要快速查找到目标 key,然而,随着向 map 中添加的 key 越来越多,key 发生碰撞的概率也越来越大。bucket 中的 8 个 cell 会被逐渐塞满,查找、插入、删除 key 的效率也会越来越低。最理想的情况是一个 bucket 只装一个 key,这样,就能达到 O(1) 的效率,但这样空间消耗太大,用空间换时间的代价太高。Go 语言采用一个 bucket 里装载 8 个 key,定位到某个 bucket 后,还需要再定位到具体的 key,这实际上又用了时间换空间。
当然,这样做,要有一个度,不然所有的 key 都落在了同一个 bucket 里,直接退化成了链表,各种操作的效率直接降为 O(n),是不行的。
©著作权归作者所有:来自51CTO博客作者wx604f04a92c6fd的原创作品,请联系作者获取转载授权,否则将追究法律责任
Go语言之map:map的用法到map底层实现分析
https://blog.51cto.com/u_15133569/5669069
2.装载因子
描述桶里面数据的装满程度.
loadFactor := count / (2^B)
装载因子(装满因子)=元数个数/桶的个数
扩容时机
在向 map 插入新 key 的时候,会进行条件检测,符合下面这 2 个条件,就会触发扩容:
map的扩容有2种机制
1、loadFactor > 6.5,触发double扩容,迫使元素顺序变化,所以为啥map要乱序
2、否则看溢出桶是否过多:
B<16时,只要溢出桶达到桶的数量,那么等量扩容
B>=16,只要overflow 溢出桶的个数>=2^15
// src/runtime/hashmap.go/mapassign
// 触发扩容时机
if !h.growing() && (overLoadFactor(int64(h.count), h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
}
// 装载因子超过 6.5
func overLoadFactor(count int64, B uint8) bool {
return count >= bucketCnt && float32(count) >= loadFactor*float32((uint64(1)<<B))
}
// overflow buckets 太多
func tooManyOverflowBuckets(noverflow uint16, B uint8) bool {
if B < 16 {
return noverflow >= uint16(1)<<B
}
return noverflow >= 1<<15
}